I’ve been sitting with a question for a few months now: what would historical figures look like if a great twentieth-century photographer had actually found them?
Not painted. Not sculpted. Not commemorated on a coin with that particular kind of posthumous dignity that tends to strip the personality out. Photographed. Found in a room. Put in front of a camera by someone who specialised in catching people off-guard.
That question turned into a project. The project turned into a pipeline. The pipeline has taught me more about how image models actually think (and more importantly, how best to work with them) than anything else I’ve worked on. These are my process notes.
The premise
Every historical figure we encounter arrives already processed.
Caesar comes to us through marble. Posthumous, idealized, the cheekbones of a god rather than a general in his fifties who was going bald and thus had strong opinions about how his hair should sit. Washington comes through Gilbert Stuart’s 1796 portrait, a pose so canonical that every subsequent representation borrows from it whether it intends to or not. Cleopatra comes through Elizabeth Taylor.
{kind=link}
Photography never had access to any of them. The medium arrived too late. And that lateness is interesting because twentieth-century portrait photography developed a set of tools specifically for doing what painting rarely attempted: catching power off-guard, stripping context, making the face carry what the official record omits.
Yousuf Karsh’s portraits don’t flatter. Diane Arbus made the ordinary strange by looking at it too directly. Richard Avedon removed all context and let the face carry everything. What would those approaches find in a Roman general? In the only woman to rule China as Emperor? In Joan of Arc at nineteen?
That’s the question the series is trying to answer. Not nostalgically. In this series, there is no noise as grain, no daguerreotype simulation, no sepia. These are clean, contemporary photographs. The anachronism is the point, not the aesthetic.
Building the matrix
My first instinct was five figures, five makers, each carefully matched 1:1 based on unique elements that might have brought them together. Think Alexander Hamilton’s unrelenting work ethic matched with Annie Leibovitz’ staged, iconic portraiture. How would she capture him if he never stopped working!
Once I started thinking about what would make this a series rather than a collection of portraits, I moved to twelve figures and twelve makers. 144 photos. At that scale, the matrix becomes readable in two directions at once: horizontally, one figure encountered by twelve different photographers; vertically, one photographer’s formal language applied across twelve completely different historical personalities. That’s when it started feeling like a real body of work rather than an interesting experiment.
The figure shortlist went through a few drafts. The instinct toward geographic diversity pulled against the instinct toward enough shared cultural weight that a viewer could move between them. The final twelve:
Julius Caesar · Cleopatra VII · Wu Zetian · Joan of Arc · Isabella I of Castile · Elizabeth I · Louis XIV · Benjamin Franklin · Catherine the Great · George Washington · Marie Antoinette · Napoleon Bonaparte
Wu Zetian might be the most interesting figure in the matrix precisely because almost no reliable visual record survives. She ruled China as Emperor for fifteen years and effectively controlled the court for decades before that. The photographs that didn’t happen because photography didn’t exist yet feel particularly pointed in her case.
The twelve makers: Leibovitz, Karsh, Man Ray, Ritts, Arbus, Penn, Beaton, Avedon, Parks, Halsman, Sander, Lange. The selection was about differentiation, not just aesthetic variety. Karsh and Halsman are both high-contrast and direct, but Karsh works in three-quarter with one hand visible and a forward lean; Halsman fills the frame with the face, uses split light, and goes for psychological intensity. These differences are load-bearing. A series where the maker traditions start to converge is a series that’s failing.
Color was decided at the maker level, not the figure level. Monochromatic makers produce black and white across all twelve of their figures. Some makers (Leibovitz, Penn, Beaton, Parks, Lange) can introduce tonal color, but kept to the level of suggestion rather than declaration: warmth in skin tones, environmental suggestion. Man Ray is the only maker permitted an actual color element, and only where it serves the conceptual reading of the piece. Color used decoratively is a failure mode I keep coming back to.
Building the agent pipeline
Running something this systematic requires a production pipeline, not a prompt list.
I ended up building four agents, each with a specific role and a specific boundary it doesn’t cross.
The Series Director holds the conceptual brief — the premise, the matrix structure, the edition standards, the failure modes. Series-level decisions live here before any generation begins.
The Figure Researcher is the one I didn’t know I needed until I’d made several bad mistakes without it. Before any prompts are written for a figure, this agent does primary source research: ancient texts, surviving portrait artefacts, numismatic evidence, modern scholarly reconstruction. It surfaces findings for review, flags which features appear across multiple independent sources versus which come from a single account, and produces an approved physical brief. Nothing goes to the Promptsmith without that brief.
The Promptsmith translates the approved brief into generation-ready prompts. It knows the technical syntax of each tool, the guidance parameter ranges, how Flux2 weights word order, the difference between a Kontext prompt and a text-to-image prompt.
The Critic
The pipeline matters because the failure mode it prevents is subtle and easy to fall into: letting the model’s training data determine the figure’s appearance. Ask an image model for Julius Caesar without a physical brief anchoring it, and you get a marble bust. You get the posthumous idealisation - because that’s what the training data is full of. The Figure Researcher exists to break that chain, to force the physical description to come from primary sources rather than from the accumulated weight of existing imagery.
Learning Flux2 the hard way
The first generation pass used fal.ai. The second used the Black Forest Labs playground directly. The results were not comparable — BFL produces meaningfully better output for this kind of work, and the platform exposes the parameters that actually matter.
The key discoveries, accumulated through iteration:
Flux2 ignores negative prompts. The documentation says this clearly. My instinct to write “not derived from sculptural portraits, no pompadour, no idealization” is strong and wrong. Everything has to be stated as a positive description of what should be present. This alone changed how I write prompts.
Word order is priority order. Flux2 weights earlier words more heavily. The structure that works: Subject → Action/pose → Style/camera → Context/lighting → Secondary details. The camera and lens specification at the end anchors the photographic quality.
The reference set problem. The first Hamilton pass produced five very different faces across five maker prompts, because each prompt was generating a new face from scratch. The fix was a reference set: generate four neutral reference images for each figure before any maker prompts are written. Straight-on, three-quarter left, three-quarter right, slight downward angle. These are the face library for the sub-series. Each maker prompt then uses the appropriate reference angle as an input image via Flux2’s editing mode, with the prompt opening “The same man, now…” to signal identity preservation before transformation.
The guidance parameter. Flux2’s editing mode doesn’t expose an image strength slider — the balance between face preservation and style transformation is controlled through a guidance value (3–8) and prompt construction. Lower guidance keeps the face. Higher guidance allows stronger style transformation at the risk of face drift. Makers whose tradition is confrontational — Avedon, Arbus, Halsman — run at higher guidance. Makers whose work is about psychological intimacy — Leibovitz, Lange — run lower.
Caesar’s face
Julius Caesar was the first figure through the full pipeline. He was harder than I expected.
The first step was research. Suetonius describes him in The Twelve Caesars (written about 175 years after Caesar’s death, but the most detailed account we have): “tall of stature, with a fair complexion, shapely limbs, a somewhat full face, and keen black eyes.” He also documents the hair specifically — Caesar would “comb forward his scanty locks from the crown of his head.” Plutarch, writing independently around the same time, adds “lean body, soft white skin.”
The visual sources are what you’d expect — mostly posthumous, mostly idealised. But there are three worth knowing about:
- The Tusculum Bust — held at the Museo di Antichità in Turin, widely considered the most reliable lifetime portrait. Full, structured face, strong cheekbones, heavy brow ridge, deep nasolabial folds, wrinkled neck. The face of a man in his fifties who has been on campaign.
- The Pantelleria Bust — found in 2003, closely matches the Tusculum. Confirms aquiline nose, forward-combed thinning hair, strong facial structure.
- The 44 BC denarius — coins struck during his lifetime are the most reliable contemporary visual record. The profile shows a prominent aquiline nose dominating the silhouette, high forehead, short hair combed forward.
.jpg){kind=link}
{kind=link}
There’s also a modern photorealistic reconstruction from Royalty Now Studios based on the Tusculum, Pantelleria, and Arles busts — useful for getting a sense of how the features might read in a living face, though it’s a research reference rather than something we’d use as an image input.
Iterating with Flux
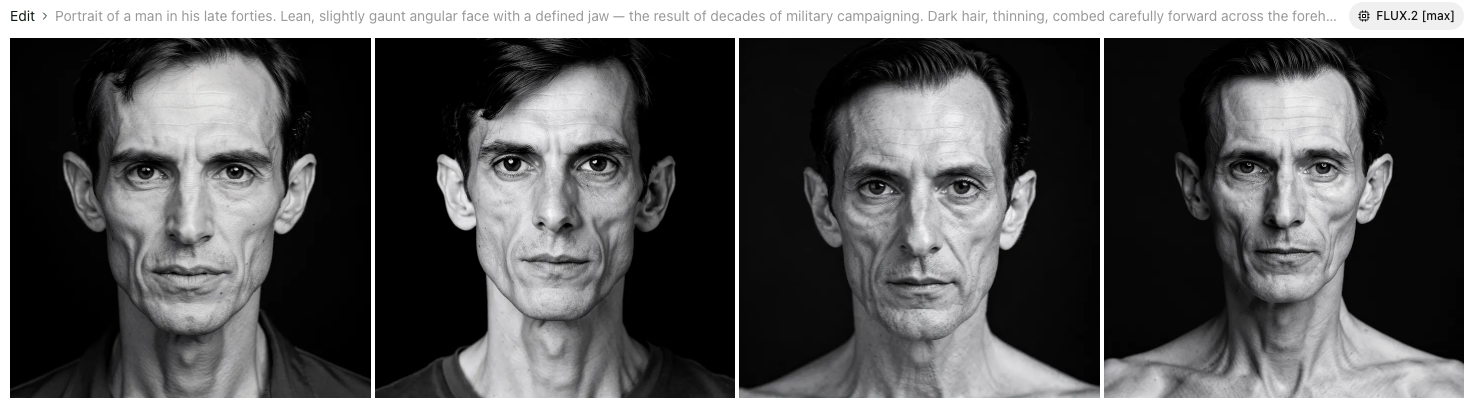 The early Caesar outputs were gaunt. Almost malnourished-looking. The error was in how I’d synthesised the sources: Plutarch’s “lean body” had leaked into the face. But Suetonius says “somewhat full face” — and the Tusculum bust confirms it. Full face, lean body, simultaneously. Once I stopped conflating them, the prompt got better.
The early Caesar outputs were gaunt. Almost malnourished-looking. The error was in how I’d synthesised the sources: Plutarch’s “lean body” had leaked into the face. But Suetonius says “somewhat full face” — and the Tusculum bust confirms it. Full face, lean body, simultaneously. Once I stopped conflating them, the prompt got better.

The hair was a separate problem that persisted across four or five iterations. Every time I wrote “combed forward,” Flux2 read it as a modern pompadour — swept back, not flat across the forehead. The fix was getting geometric: “short horizontal strands combed directly forward and flat across the forehead, not swept back.” The specific geometry mattered in a way that “combed forward” alone didn’t.
The third problem was modernity. An output with correct bone structure and a reasonable hair arrangement still read as a contemporary professional rather than a first-century general and statesman. What was missing were the Tusculum details I’d been underweighting: the heavy brow ridge, the deep nasolabial folds, the weather-beaten textured skin. A face that has spent decades on campaign looks different from a face that has spent decades in an office, and the prompt has to earn that difference explicitly.
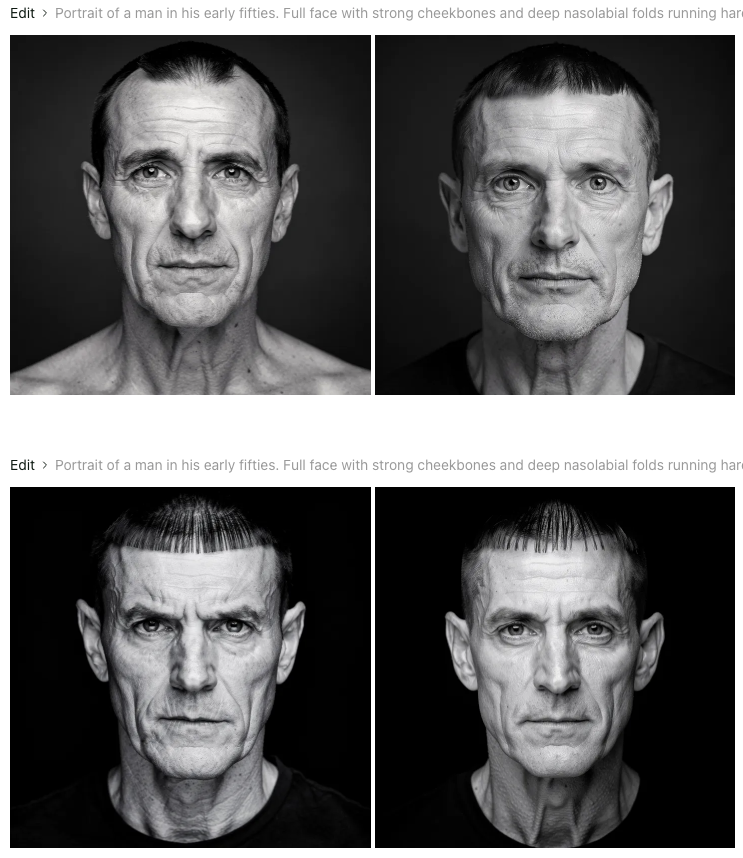
The current R001 prompt — the text-to-image prompt used to generate the neutral reference face:
Portrait of a man in his early fifties. Full, well-structured face carrying genuine weight — strong cheekbones, defined chin, heavy brow ridge casting shadow over deep-set eyes, the face of someone who commands rooms without raising his voice. Prominent aquiline nose, the defining feature of the profile. Deep nasolabial folds. Hairline sharply receding at the temples, dark hair short, combed directly forward across a high forehead in short horizontal strands — the arrangement specific, effortful, vain. Weather-beaten fair skin, textured and lined, complexion pale beneath years of campaign. Dark piercing eyes. Lines of age on the face and neck. Shot on Hasselblad 503CW, 120mm lens, f/4. Broad even studio lighting, both sides of the face fully lit, catchlight in both eyes. Expression neutral and composed, direct gaze to camera. Deep black background, cropped at collarbone. Monochromatic black and white.
We have an output that holds the right register. The next pass is a targeted edit for face fullness and hair density — using Kontext, which can take an existing image and apply a single precise instruction while preserving everything else. Then three angle variants from the locked R001.



With our four reference angles in place, we will move on to our twelve maker prompts.
The session test for whether a maker prompt output is worth keeping: does it feel caught or constructed? The pose is not neutral. The expression is a specific psychological state, not a default. The lighting is doing something the figure cannot control. If it reads as a portrait sitting, it fails.
Caesar-series is the first sub-series of twelve. The 12x12 matrix is the complete work. More soon.
Exposure-series is currently in production. Reference images are being established for Caesar-series.